
Kann man mit Large Language Models (LLMs) wie GPT künstliche Datensätze, sogenannte „Silicon Samples“ generieren, die menschliches Antwortverhalten abbilden können? Darum ging es in meiner Kolumne im Dezember. Meine Einschätzung war eher zurückhaltend, schließlich haben Forscher um Thilo Hagendorff in ihrer Studie in “Nature Computational Science” jüngst gezeigt, dass neuere Versionen von GPT unheimlich gut sind, die fachlich „richtigen“ Antworten zu finden. Wenn es aber darum geht, menschliches Antwortverhalten mit all seinen Schwächen abzubilden, liegen die Modelle häufig daneben.
Nun sind aber Thilo Hagendorff und Kollegen nicht die einzigen, die sich dieser Fragestellung gewidmet haben. Wie sieht es in anderen Forschungsfeldern aus? Und was lernen wir aus den Ergebnissen? Mit diesen Fragen habe ich mich gemeinsam mit Susanne Adler, Lea Rau (Ludwig-Maximilians-Universität München) und Bernd Schmitt (Columbia Business School) in unserem Forschungsaufsatz „Using large language models to generate silicon samples in consumer and marketing research: Challenges, opportunities, and guidelines“ auseinandergesetzt, der gerade in “Psychology & Marketing” erschienen ist.
Vergleich von synthetischen und menschlichen Beobachtungen
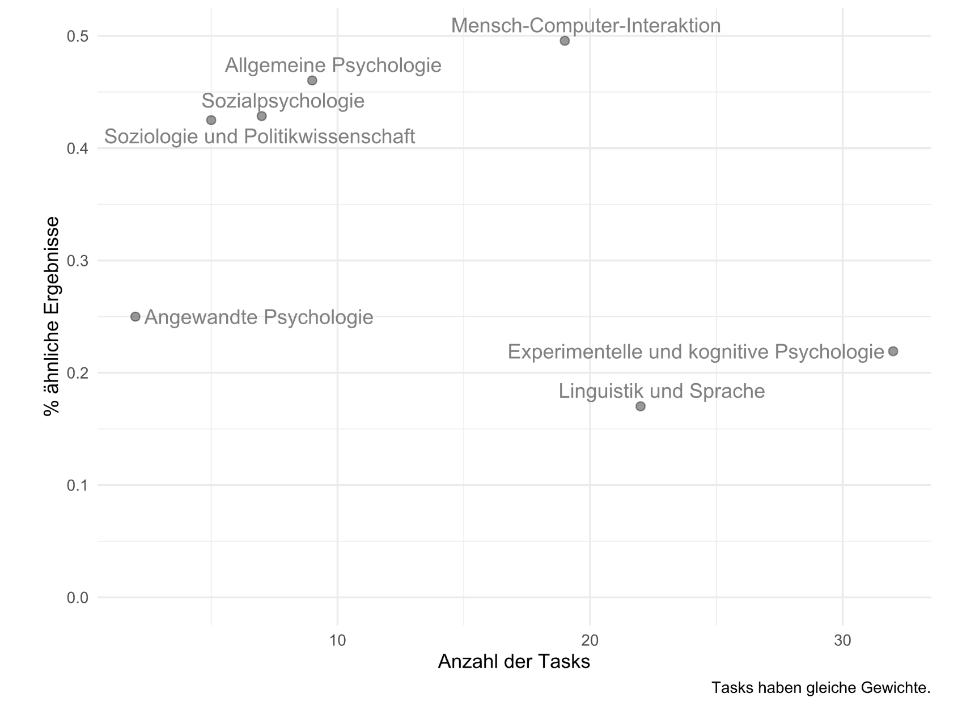
Die Ergebnisse unserer systematischen Literaturanalyse von 28 Studien, die 285 Vergleiche von synthetischen und menschlichen Beobachtungen auf der Basis von 96 verschiedenen Aufgabenstellungen (Tasks) vorgenommen haben, scheinen die Ergebnisse von Hagendorff und Koautoren zu bestätigen. In gerade einmal 35 Prozent aller 285 Vergleiche schlussfolgerten die Autoren, dass LLMs und menschliche Probanden dasselbe oder zumindest ein ähnliches Antwortverhalten an den Tag legen.
So konnten LLMs im Bereich der Linguistik gerade einmal knapp 15 Prozent der menschlichen Antwortmuster abbilden. Im Gegensatz hierzu konnten LLMs im Bereich der Mensch-Computer-Interaktion mit einer Erfolgsquote von knapp über 40 Prozent punkten (Abbildung 1). Die gute Nachricht: Durch ein passendes Anlernen mit Hilfe von Prompt-tuning, bei dem der Anwender dem Modell mindestens eine richtige Antwort vorgibt (zum Beispiel: „Hier ist ein Beispiel für einen Kunden, der sich über die Servicequalität beschwert: …“), konnte die Erfolgsquote deutlich gesteigert werden.
LLMs in frühen Prozessphasen relevant
Sind LLMs für die Marktforschung also von geringem Nutzen? Ganz und gar nicht! Aber die Frage ist, an welcher Stelle des Marktforschungsprozesses sie sinnvoll eingesetzt werden können. Unser Take: LLMs sind vor allem in den frühen Phasen des Forschungsprozesses relevant, in denen es häufig darum geht, das Design einem Stresstest zu unterziehen. Sind die Items in meinem Fragebogen verständlich? Wie wirken verschiedene Varianten von Werbemitteln oder Verpackungen? Wir zeigen in unserem Artikel, dass man solche Fragen sehr gut durch LLMs wie GPT beantworten kann.
Wenn es aber um umfassende Studien geht, ist in vielerlei Hinsicht Vorsicht geboten. So unterliegen die Trainingsdaten von GPT beispielsweise einem kulturellen Bias der größer ausfällt, je höher die kulturelle Distanz zu den USA ist. Kein Wunder, schließlich werden LLMs vor allem auf Basis von US-amerikanischen Daten trainiert. Zudem darf man sich durchaus fragen, was eigentlich die Grundgesamtheit sein soll, auf der LLMs wie GPT basieren. Denn auch mit noch so vielen Daten lassen sich die Grundlagen der Stichprobentheorie nicht aus den Angeln heben. In diesen Fällen ist es also ratsam, zunächst eine Benchmark-Studie mit menschlichen Probanden durchzuführen. Klar, das kostet Zeit und Geld, aber immer noch besser als die Entscheidung auf synthetischen Daten zu stützen, die wenig mit den Einstellungen und Intentionen der Zielgruppe zu tun haben. Denn bei aller durchaus berechtigten Euphorie: Marketing bleibt ein people’s business.
Quellen
Hagendorff, T., Fabi, S., & Kosinski, M. (2023). Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nature Computational Science, 3, 833–838.
Sarstedt, M., Adler, S. J., Rau, L., & Schmitt, B. (2024). Using large language models to generate silicon samples in consumer and marketing research: Challenges, opportunities, and guidelines. Psychology & Marketing, erscheint demnächst.
Open access: https://onlinelibrary.wiley.com/doi/10.1002/mar.21982
